Latency Budgets From First Principles
When a page feels slow, users rarely care which layer lost the time. They only feel the total. That is why I like latency budgets: they force every subsystem to spend from the same finite envelope.
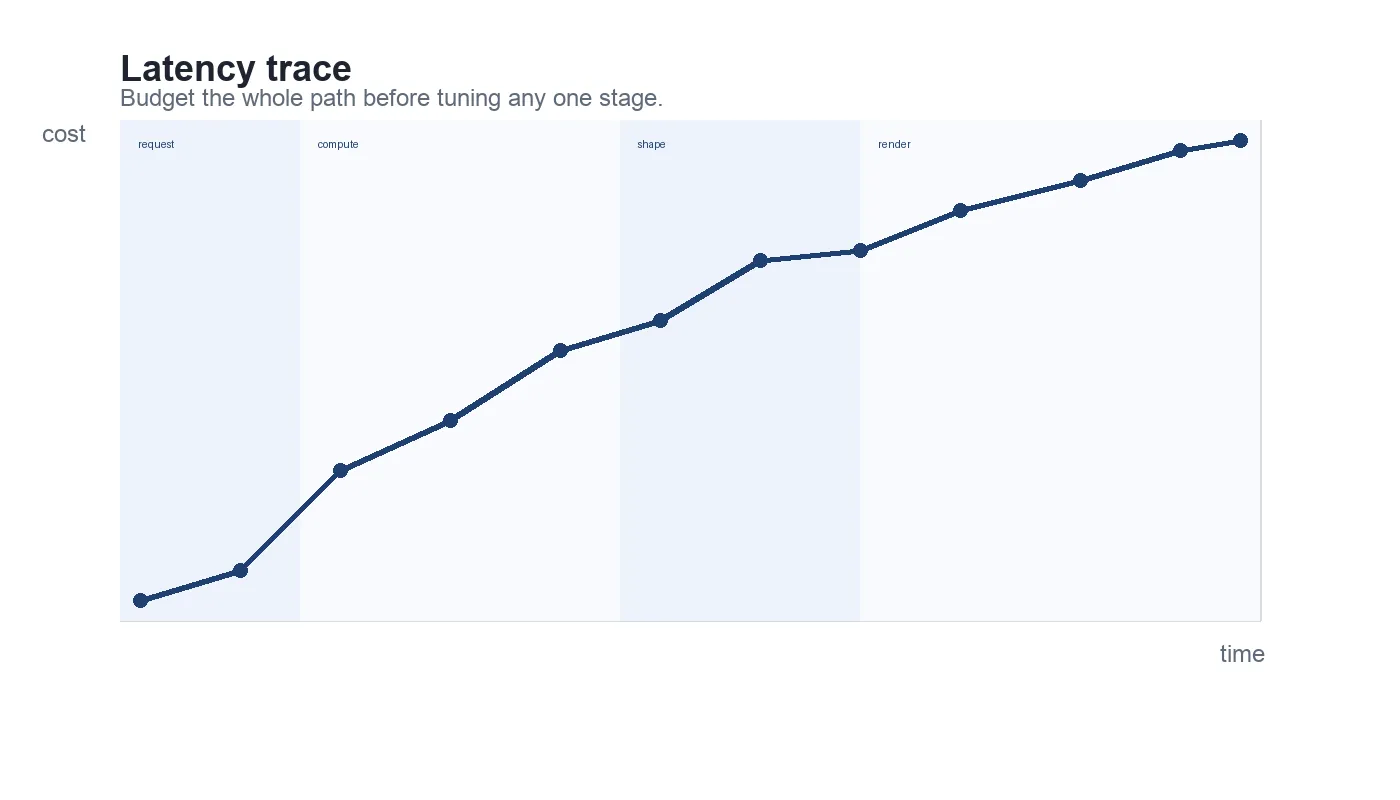
Suppose we want the median interaction to stay under 120 ms. A rough decomposition might look like this:
| Phase | Target |
|---|---|
| Network request | 35 ms |
| Backend compute | 30 ms |
| Data shaping | 20 ms |
| Rendering | 35 ms |
The point is not that these numbers are perfect. The point is that once the budget exists, every optimization can be evaluated against a shared target instead of a vague wish to “make it faster.”
Here is a tiny benchmark harness that captures the same mindset:
package main
import (
"fmt"
"time"
)
func measure(name string, f func()) {
started := time.Now()
f()
fmt.Printf("%s took %s\n", name, time.Since(started))
}
func main() {
measure("render", func() {
time.Sleep(18 * time.Millisecond)
})
}This kind of harness is not meant to replace production tracing. It exists to answer a smaller question early: is this approach even in the right order of magnitude?
My rule of thumb is simple:
- Budget the full path.
- Measure the largest term.
- Remove whole classes of work before tuning the remaining pieces.
That third step is where most of the leverage hides. A cache hit is better than a faster query. A precomputed index is better than a clever scan. A smaller payload is better than a more heroic parser.